

Retrieval-Augmented Generation (RAG) has become one of the most important architectural patterns in modern AI systems. It powers enterprise chatbots, research assistants, customer support tools, and internal knowledge systems across nearly every industry. But while RAG solved a critical problem for large language models (LLMs), it was never meant to be the final destination.
RAG was a necessary step, not the end goal.
To understand where AI systems are going next, we need to look at how RAG evolved, why Agentic RAG emerged, and why memory, not retrieval, is the true foundation of intelligent systems.
The Original Problem: LLMs Know Language, Not Truth
Large language models are exceptional at generating fluent, human-like text. What they lack is grounded knowledge. Their training embeds vast statistical patterns of language into model parameters, but that knowledge is:
- Frozen at training time
- Difficult to update
- Not inherently verifiable
This creates a dangerous illusion: LLMs often sound confident even when they’re wrong. These “hallucinations” are not bugs, they’re a natural consequence of predicting the next token without access to authoritative sources.
RAG emerged as a solution to this problem.

What Retrieval-Augmented Generation Really Does
Retrieval-Augmented Generation allows an LLM to consult external knowledge before answering. Instead of relying solely on internal parameters, the model retrieves relevant documents, passages, or records and uses them to ground its response.
At a high level, RAG works like this:
- A user submits a query
- The query is converted into a vector embedding
- A vector database retrieves semantically similar content
- Retrieved content is passed to the LLM
- The LLM generates an answer grounded in retrieved sources
The courtroom analogy explains this well. The LLM is the judge, capable of reasoning and articulation, but it relies on a clerk to fetch relevant precedents from the law library. The clerk is the retrieval system, and the library is the knowledge base.
This approach dramatically improves accuracy, reduces hallucinations, and enables citation-backed answers.
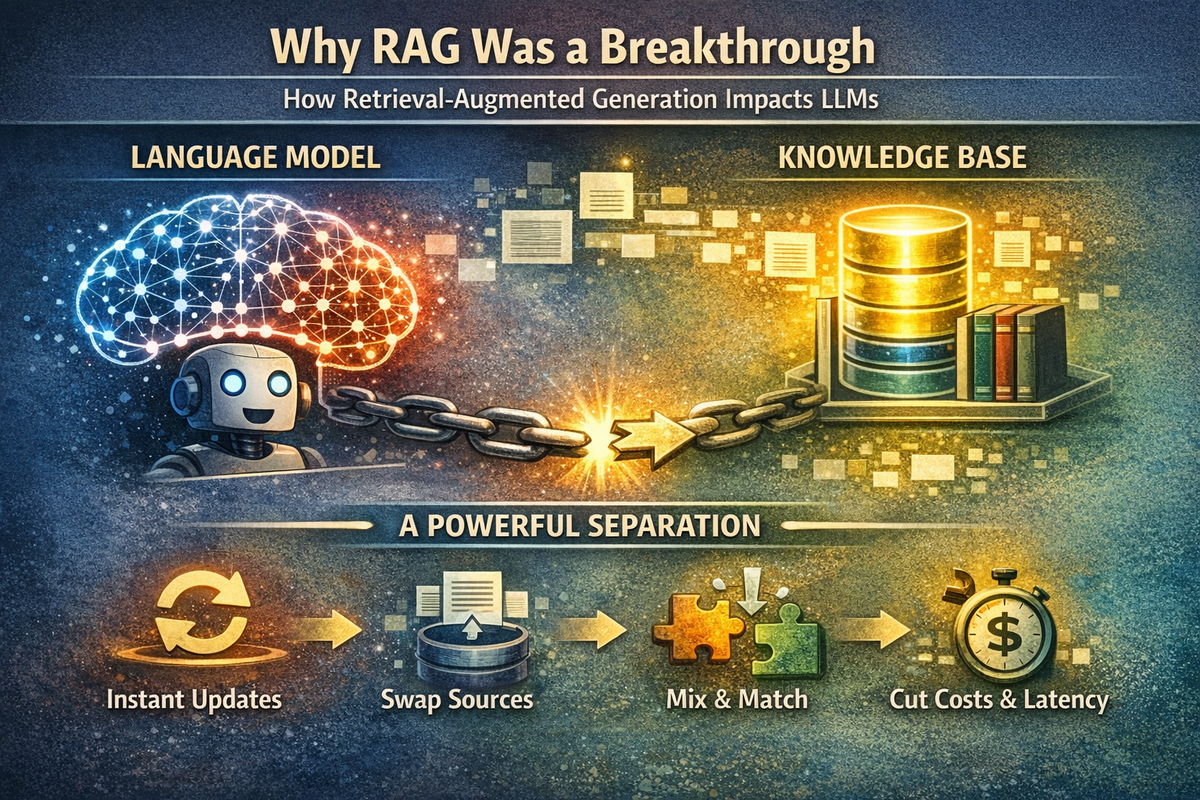
Why RAG Was a Breakthrough
The term “retrieval-augmented generation” was introduced in a 2020 research paper led by Patrick Lewis. While the acronym may be unfortunate, the impact was profound.
RAG introduced a powerful separation of concerns:
- Language ability lives in the model
- Knowledge lives outside the model
This separation unlocked several advantages:
- Knowledge can be updated without retraining
- New data sources can be swapped in instantly
- Any LLM can be paired with any knowledge base
- Costs and latency are reduced compared to fine-tuning
RAG transformed LLMs from static text generators into dynamic knowledge engines.
Native RAG: The Standard Pipeline
Most RAG systems today follow what’s known as Native RAG, a deterministic, linear pipeline:
- Query processing and embedding
- Similarity search over a vector database
- Reranking retrieved results
- Answer synthesis by the LLM
Native RAG is effective, scalable, and relatively easy to implement. It works well for:
- Search and Q&A
- Customer support
- Documentation assistants
- Internal knowledge bots
But it has a fundamental limitation.
Native RAG retrieves every time, regardless of whether retrieval is necessary or useful. It cannot reason about whether to retrieve, which source to trust, or how to adapt its strategy based on context. Most importantly, it has no memory.
Once the answer is generated, everything is forgotten.
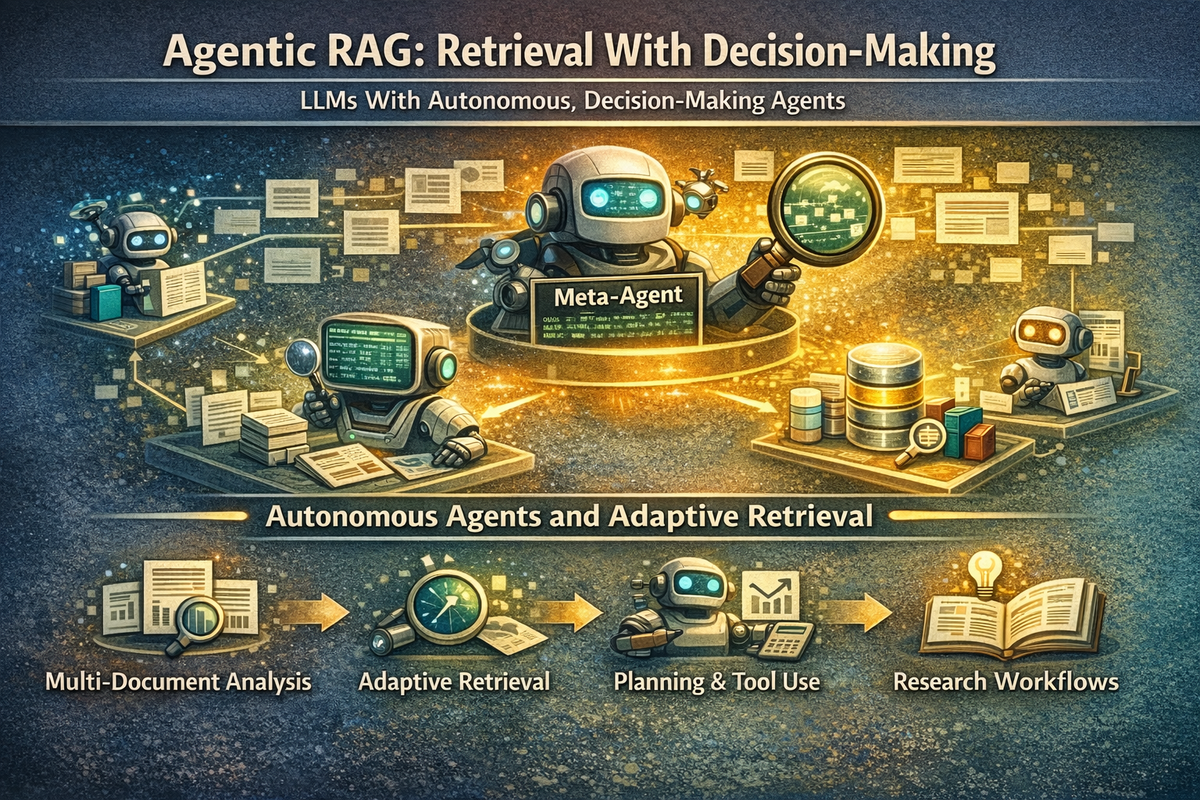
Agentic RAG: Retrieval With Decision-Making
Agentic RAG emerged to solve this rigidity.
Instead of treating retrieval as a mandatory step, Agentic RAG introduces autonomous agents that can decide:
- If retrieval is needed
- Which sources to query
- How deeply to search
- How to validate retrieved information
In many implementations, each document or data source has its own agent, coordinated by a meta-agent that synthesizes outputs and manages reasoning. This enables:
- Multi-document comparison
- Research-style workflows
- Tool calling and planning
- Adaptive retrieval strategies
Agentic RAG turns the system from a pipeline into a decision-making workflow.
However, even Agentic RAG has a hard ceiling.
The Core Limitation: Still Read-Only
Agentic RAG systems are smarter, but they are still fundamentally stateless. They can read from external knowledge, reason about it, and generate high-quality answers, but they cannot learn from experience.
They do not remember:
- User preferences
- Past interactions
- Decisions they made
- Mistakes they corrected
Each interaction starts from zero.
This is where the real evolution begins.
Memory: The Missing Foundation of Intelligence
True intelligence is not just reasoning, it’s learning over time.
Memory transforms AI systems from: One-shot responders into Continually improving agents
The key shift is from read-only retrieval to read-write memory.
Types of Memory in AI Agents
Effective agent memory is structured, not just a vector dump:
- Short-Term Memory (STM): Lives in the context window, fast but transient
- Long-Term Memory (LTM): Persistent and expandable, divided into:
- Semantic memory: facts and concepts
- Episodic memory: past interactions and events
- Procedural memory: learned behaviors and habits
With memory, agents can personalize responses, adapt strategies, and improve without retraining.

The New Engineering Challenge
As AI systems move toward memory-centric architectures, the core engineering problem changes.
The focus shifts from: “How do we retrieve better chunks?” to: “How do we manage memory responsibly?”
Key questions include:
- When should an agent write new memory?
- How are conflicting memories resolved?
- What should be forgotten, and when?
- How do multiple agents synchronize shared memory?
- Who owns truth in a multi-agent swarm?
Memory introduces risks, corruption, drift, inconsistency, but it is unavoidable if AI systems are to become truly adaptive.
Why RAG Was Never the End Goal
RAG was a critical milestone. Agentic RAG pushed the boundary further. But neither delivers true learning.
The real progression is clear:
- RAG: Read-only lookup
- Agentic RAG: Read-only with decisions
- Agent Memory: Read-write intelligence
The systems that win in the next generation will not be defined by bigger models or faster retrieval. They will be defined by unified memory infrastructures that persist, evolve, and synchronize across agents.
Memory is not a feature. Memory is the foundation.
And once AI systems can remember, learn, and adapt, RAG finally becomes what it was always meant to be: just one component in a much larger intelligence architecture.