

Large language models (LLMs) are incredible at generating human‑like text, but they have serious gaps: they often hallucinate facts, lack up‑to‑date knowledge, and cannot remember context from one conversation to the next. To solve these limitations, developers reach for techniques such as retrieval‑augmented generation (RAG) and agent memory, but the discourse often frames these techniques as mutually exclusive.
In reality, the next generation of AI agents needs both. Retrieval improves factual grounding while memory provides continuity and personalization. Memvid embraces this synthesis by combining RAG with a self‑contained memory layer stored in a single portable file.
This blog unpacks why RAG is often mistaken for memory, why it still falls short of true memory, and how an AI memory layer like Memvid brings both systems together to create smarter agents.
Why RAG Feels Like Memory, and Why It Isn’t
At first glance, RAG seems to provide memory. When a model lacks the right context and produces wrong answers, one solution is to retrieve relevant documents at inference time. Injecting external facts into the prompt does three things:
- Anchors answers to external data: RAG grounds responses in factual sources rather than relying solely on model weights.
- Reduces hallucination: By retrieving real documents instead of guessing, the model is less likely to invent information.
- Extends recall beyond the context window: Because RAG can pull from large corpora, it acts like an “open‑book” test.
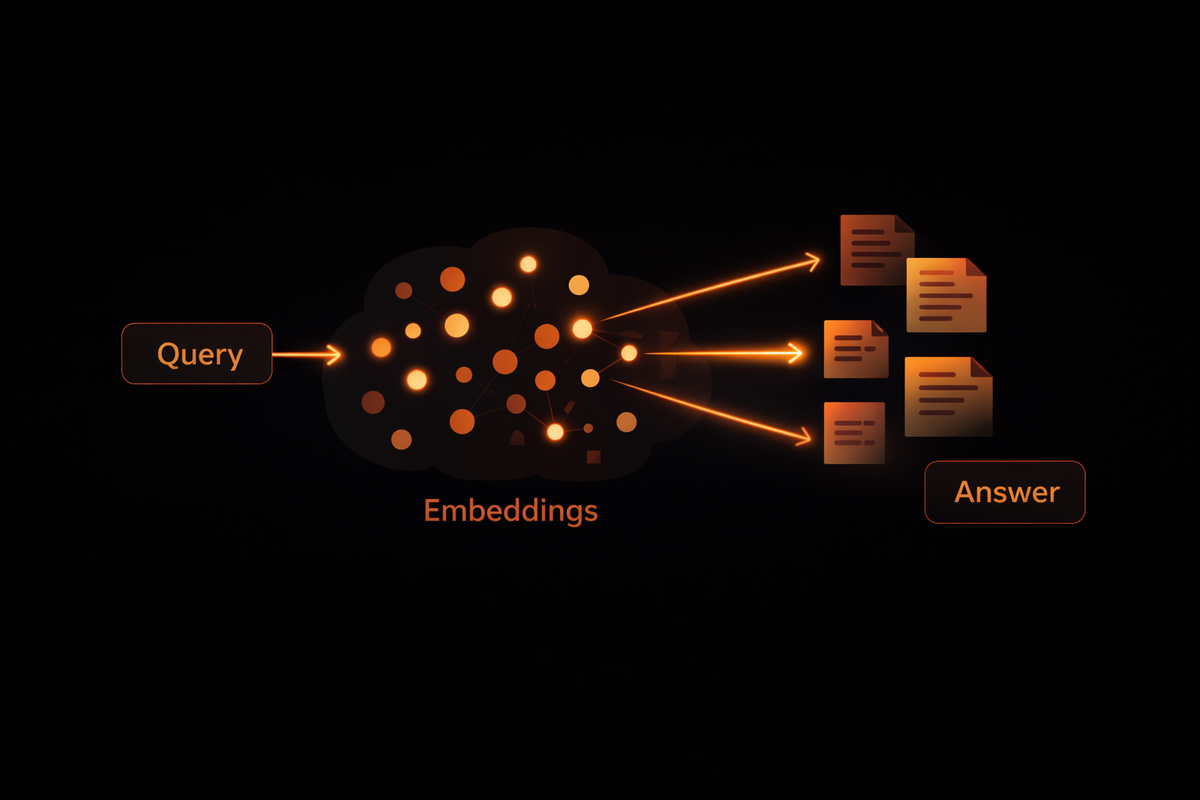
This retrieval step looks like remembering because the model provides more accurate responses by pulling relevant context. But conceptually, RAG is just stateless similarity search.
The workflow is simple: Query → Embedding → Vector search → Top‑(k) chunks → Inject into prompt → Generate answer, and then discard context
RAG has no notion of time, truth, conflict, or update. Each query is independent; the system simply asks, “What text is closest in embedding space right now?”. It doesn’t know if a fact is still true, which fact supersedes another, or what has changed since the last interaction.
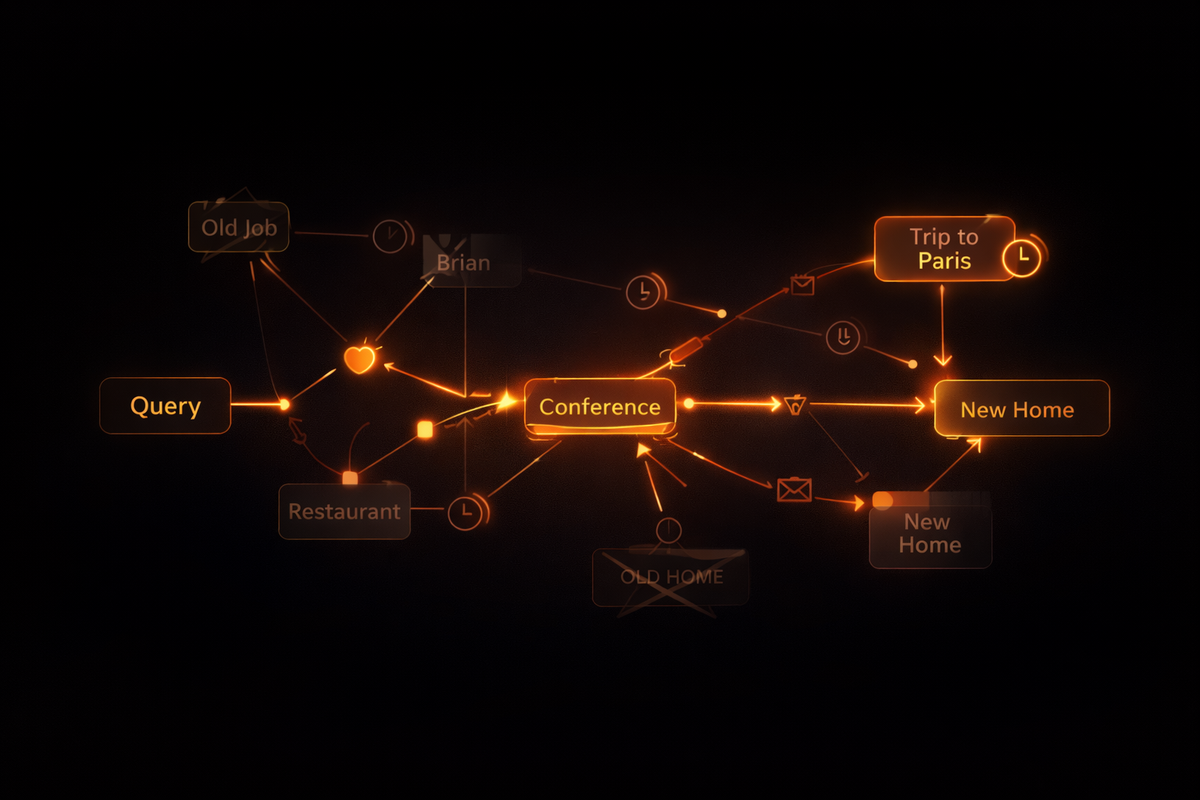
The Persistence Problem
Because RAG lacks state, it fails at tasks that require state transitions. Here’s an example scenario: if a user says they love Nike sneakers, later reports they broke, then switches to Converse, a RAG system will still recommend Nike because that phrase is most semantically similar to the query. The system does not recognize that the later event invalidates the earlier preference. The missing capabilities of RAG are:
- Temporal sequence: understanding which fact came first and when it became invalid.
- Causal relationships: connecting events (broken shoes → disappointment → switch).
- Fact invalidation: superseding outdated facts with updated ones.
Even if you bolt on timestamps or re‑ranking, you’re still working on a substrate that has no native concept of overwrite or conflict resolution. That’s why “agentic RAG” still isn’t memory, it’s retrieval with more sophisticated choreography.
What True Memory Requires
Memory isn’t “more retrieval.” It implies stateful belief management. A real memory system must support:
- Write semantics: a new fact replaces or updates a previous fact.
- Forgetting or decay: outdated or irrelevant information fades away to prevent clutter.
- Conflict resolution: when two facts conflict, the system decides which is valid.
- Consolidation: multiple events merge into a stable belief.
- Identity binding: facts are linked to specific users or entities.
RAG and Memory Are Complementary
Rather than viewing RAG and memory as competing approaches, it’s more helpful to see them as complementary layers. RAG helps an agent answer “What is true now?” by retrieving up‑to‑date facts from external sources.
Memory answers “What has changed?” and “What do I remember about you?” Traditional stateless RAG systems answer one query at a time, but real workflows span sessions, decisions and evolving user needs. RAG and memory solve different but complementary problems: retrieval ensures your system knows what’s currently true, while memory adds temporal and personal context.
RAG is appropriate for static document Q&A or knowledge lookup, whereas agent memory is needed for stateful workflows, continuity and learning. We need to differentiate between stateless documents and stateful memories, how hybrid systems can use both types: RAG for universal knowledge and memory for user‑specific facts.
When You Need RAG
RAG excels at grounding models on broad knowledge bases and frequently updated corpora. It’s ideal for:
- Static documentation and knowledge bases.
- Research queries requiring access to large amounts of information.
- Reducing hallucinations by anchoring answers to external facts
When You Need Memory
Memory shines in contexts that involve continuity and personalization, such as:
- User preferences and conversation history.
- Persistent facts that evolve over time (e.g., moving from Paris to Amsterdam).
- Long‑running workflows where decisions depend on past interactions, like programming assistants or support agents.
The Power of Hybrid Retrieval
The most capable systems blend RAG and memory. Future GenAI systems should retrieve what’s true now and remember what was relevant before.
Hybrid architectures may perform semantic search, keyword search and graph traversal in combination, then fuse results. This yields fast, accurate retrieval with context‑aware reasoning.
Enter Memvid: A Unified RAG + Memory Layer in One File
Memvid misleading the charge in the “RAG and memory” philosophy by providing a single portable memory file that can be plugged into any AI agent with just a few lines of code. This file acts as a self‑contained database: it stores both the agent’s knowledge from external documents and its evolving memory of user interactions.

How Memvid Stores Information
Instead of relying on a cloud‑hosted vector database, Memvid encapsulates everything in a file that your
code can read, write and update. Information is organized into Smart Frames, containing:
- Original content (text, documents or even multimodal data).
- Embeddings for semantic retrieval.
- Timestamps to track when a fact was learned and when it became invalid.
- Relationships to link facts by entities, context or causality.
These frames allow Memvid to unify long‑term memory and external information retrieval into one system. When a query arrives, Memvid can activate only the relevant frames by meaning, keyword, time or context and reconstruct an answer instantly.
The result is millisecond‑level retrieval without network latency. Because the file is portable and can be persisted locally, there are zero cloud dependencies, a critical feature for privacy or offline applications.
Why a Single File Matters
Traditional RAG pipelines require an external vector database or knowledge graph hosted in the cloud. These introduce latency, cost and complexity. Memvid’s file‑based approach offers:
- Portability: The memory travels with the application, simplifying deployment and versioning.
- Model‑agnostic integration: Any LLM can load the memory file without proprietary dependencies. Persistence across sessions: The file is updated as the agent learns, enabling long‑term state.

Combining RAG and Memory Inside Memvid
Memvid doesn’t choose between retrieval and memory, it does both. When you embed external documents into the Smart Frame store, those embeddings serve as the retrieval layer similar to RAG. At the same time, the file records the agent’s interactions and updates existing frames when facts change. This means:
- Grounded responses: The agent can reference external knowledge, reducing hallucinations and providing factual answers.
- Personalized continuity: The same agent remembers user preferences, past decisions and evolving state across sessions.
- Conflict resolution: When new information supersedes old, the Smart Frame updates the timestamp or marks the old fact as invalid, preserving temporal chains.
- Fast local retrieval: Because data is stored in a one file, look‑ups occur in milliseconds without network delays.
In essence, Memvid implements the hybrid retrieval paradigm in the most efficient way: combining semantic search with relational and temporal reasoning. Our file‑based memory layer plays the role of a knowledge graph, tracking relationships and time, while embedded vectors support rapid similarity search.
Why RAG AND Memory Is the Future
Treating RAG and memory as opposing solutions is a false choice. RAG offers immediate grounding but remains stateless and impersonal, whereas memory alone can become stale if it isn’t refreshed by retrieval. Vector databases alone are insufficient; systems need semantic, episodic, procedural and declarative memory types.
Memvid’s design embraces this insight: retrieval and memory aren’t substitutes, they’re complements. Retrieval ensures your agent answers correctly based on current, external data. Memory ensures the agent answers coherently based on past interactions and changing facts. By storing both in a single portable file, Memvid makes it easy for developers to add stateful, context‑aware intelligence to their AI agents without heavy infrastructure.
RAG is an essential tool for grounding AI models, but it is not memory. True memory requires stateful belief management, temporal awareness, conflict resolution and identity binding, capabilities that vector search alone can’t provide.
Memvid takes this philosophy to heart, unifying RAG and memory inside a single portable memory file. Our Smart Frame architecture stores content, embeddings, timestamps and relationships, enabling both rapid retrieval and rich memory management. With just a few lines of code, developers can plug Memvid into an AI agent and give it the ability to know more and remember better, without a cloud dependency.
It’s time to stop debating RAG vs Memory and start building systems that leverage RAG AND Memory. Memvid provides an elegant blueprint for this future.